使用 Containerlab + Kind 快速部署 Cilium BGP 环境
1.1 Cilium 介绍
Cilium 是一款基于 eBPF 技术的 Kubernetes CNI 插件,Cilium 在其官网上对产品的定位为 “eBPF-based Networking, Observability, Security”,致力于为容器工作负载提供基于 eBPF 的网络、可观察性和安全性的一系列解决方案。Cilium 通过使用 eBPF 技术在 Linux 内部动态插入一些控制逻辑,可以在不修改应用程序代码或容器配置的情况下进行应用和更新,从而实现网络、可观察性和安全性相关的功能。
1.2 Cilium BGP 介绍
BGP(Border Gateway Protocol,边界网关协议)是一种用于 AS(Autonomous System,自治系统)之间的动态路由协议。BGP 协议提供了丰富灵活的路由控制策略,早期主要用于互联网 AS 之间的互联。随着技术的发展,现在 BGP 协议在数据中心也得到了广泛的应用,现代数据中心网络通常是基于 Spine-Leaf 架构,其中 BGP 可用于传播端点的可达性信息。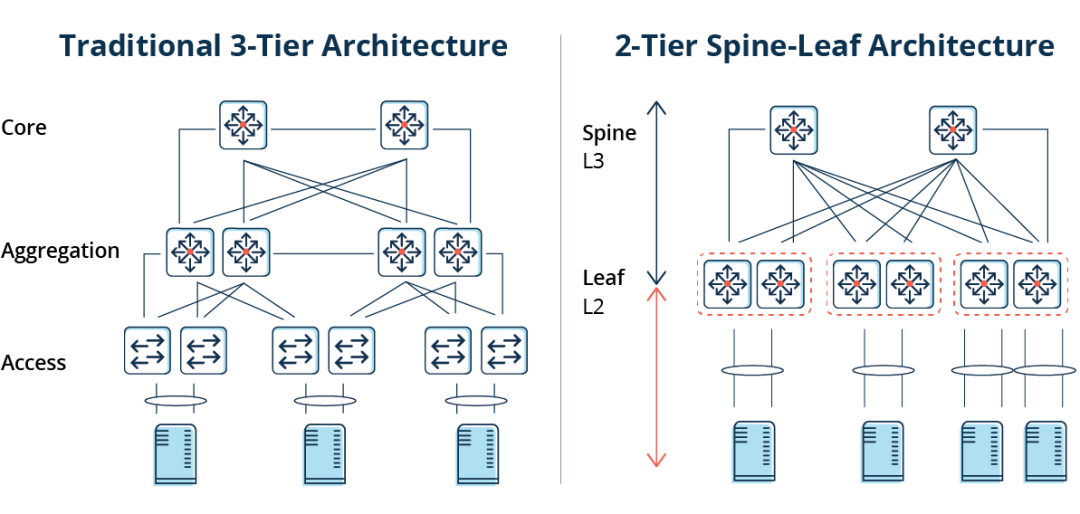
Leaf 层由接入交换机组成,这些交换机会对来自服务器的流量进行汇聚并直接连接到 Spine 或网络核心,Spine 交换机以一种全网格拓扑与所有 Leaf 交换机实现互连。
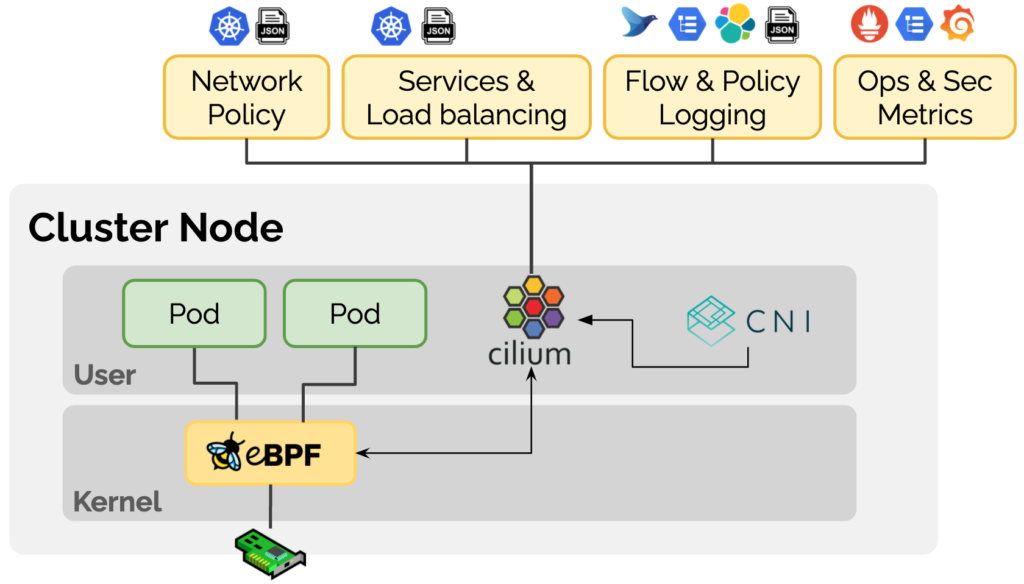
随着 Kubernetes 在企业中的应用越来越多,这些端点有可能是 Kubernetes Pod,为了让 Kubernetes 集群外部的网络能够通过 BGP 协议动态获取到访问的 Pod 的路由,显然 Cilium 应该引入对 BGP 协议的支持。
在 Cilium 最初在 1.10 版本中引入了 BGP,通过为应用分配 LoadBalancer 类型的 Service 并结合 MetalLB,从而向 BGP 邻居宣告路由信息。
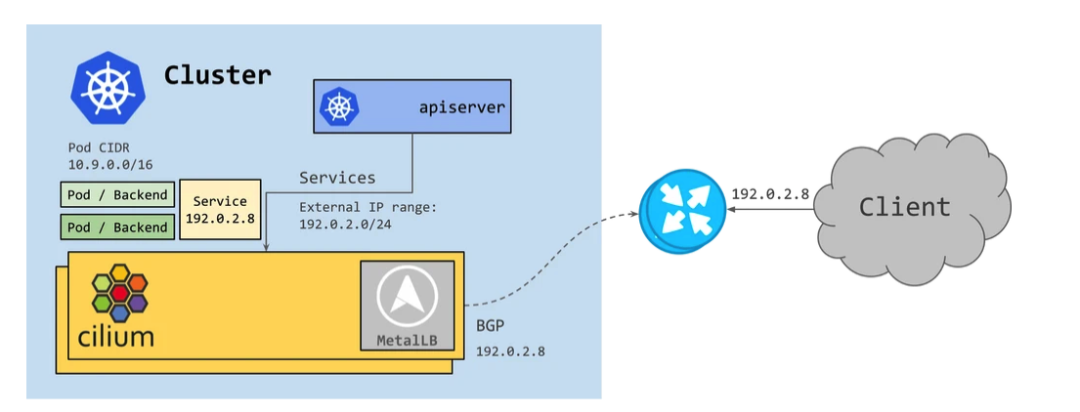
然而,随着 IPv6 的使用持续增长,很明显 Cilium 需要 BGP IPv6 功能 – 包括 Segment Routing v6 (SRv6)。MetalLB 目前通过 FRR 对 IPv6 的支持有限,并且仍处于试验阶段。Cilium 团队评估了各种选项,并决定转向功能更丰富的 **GoBGP [1]**。
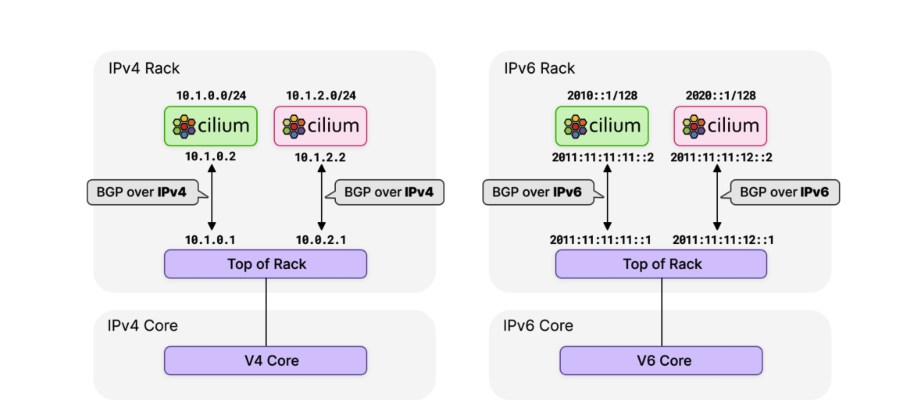
在最新的 Cilium 1.12 版本中,启用对 BGP 的支持只需要设置 --enable-bgp-control-plane=true 参数,并且通过一个新的 CRD CiliumBGPPeeringPolicy 实现更加细粒度和可扩展的配置。
- 使用
nodeSelector 参数通过标签选择,可以将相同的 BGP 配置应用于多个节点。
- 当
exportPodCIDR 参数设置为 true 时,可以动态地宣告所有 Pod CIDR,无需手动指定需要宣告哪些路由前缀。
neighbors 参数用于设置 BGP 邻居信息,通常是集群外部的网络设备。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| apiVersion: "cilium.io/v2alpha1"
kind: CiliumBGPPeeringPolicy
metadata:
name: rack0
spec:
nodeSelector:
matchLabels:
rack: rack0
virtualRouters:
localASN: 65010
exportPodCIDR: true
neighbors:
peerAddress: "10.0.0.1/32"
peerASN: 65010
|
1.3 Kind 介绍
**Kind [2]**(Kubernetes in Docker)是一种使用 Docker 容器作为 Node 节点,运行本地 Kubernetes 集群的工具。我们仅需要安装好 Docker,就可以在几分钟内快速创建一个或多个 Kubernetes 集群。为了方便实验,本文使用 Kind 来搭建 Kubernetes 集群环境。
1.4 Containerlab 介绍
Containerlab [3] 提供了一种简单、轻量的、基于容器的编排网络实验的方案,支持各种容器化网络操作系统,例如:Cisco,Juniper,Nokia,Arista 等等。Containerlab 可以根据用户定义的配置文件,启动容器并在它们之间创建虚拟连接以构建用户定义网络拓扑。
1
2
3
4
5
6
7
8
9
10
11
12
13
| name: sonic01
topology:
nodes:
srl:
kind: srl
image: ghcr.io/nokia/srlinux
sonic:
kind: sonic-vs
image: docker-sonic-vs:2020-11-12
links:
- endpoints: ["srl:e1-1", "sonic:eth1"]
|
容器的管理接口会连接到名为 clab 的 bridge 类型的 Docker 网络中,业务接口通过配置文件中定义的 links 规则相连。这就好比数据中心中网络管理对应的带外管理(out-of-band)和带内管理(in-band)两种管理模式。
Containerlab 还为我们提供了丰富的实验案例,可以在 Lab examples[4] 中找到。我们甚至可以通过 Containerlab 创建出一个数据中心级别的网络架构(参见 5-stage Clos fabric[5])
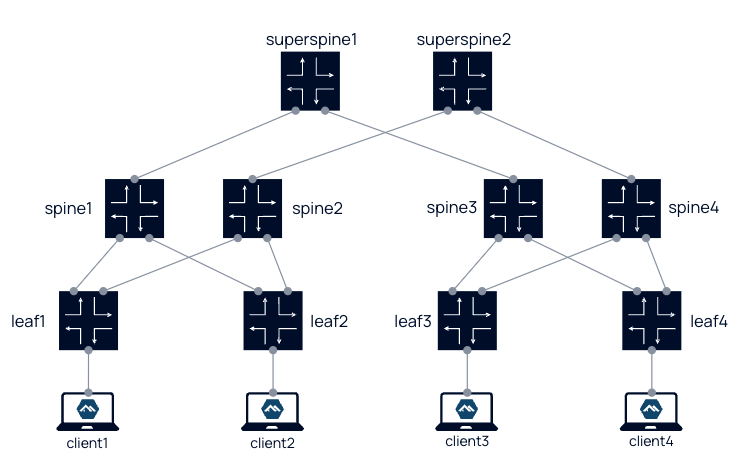
2 前提准备
请根据相应的操作系统版本,选择合适的安装方式:
本文所用到的配置文件可以在 https://github.com/cr7258/kubernetes-guide/tree/master/containerlab/cilium-bgp 中获取。
3 通过 Kind 启动 Kubernetes 集群
准备一个 Kind 的配置文件,创建一个 4 节点的 Kubernetes 集群。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
kind: Cluster
name: clab-bgp-cplane-demo
apiVersion: kind.x-k8s.io/v1alpha4
networking:
disableDefaultCNI: true
podSubnet: "10.1.0.0/16"
nodes:
- role: control-plane
kubeadmConfigPatches:
- |
kind: InitConfiguration
nodeRegistration:
kubeletExtraArgs:
node-ip: 10.0.1.2 # 节点 IP
node-labels: "rack=rack0" # 节点标签
- role: worker
kubeadmConfigPatches:
- |
kind: JoinConfiguration
nodeRegistration:
kubeletExtraArgs:
node-ip: 10.0.2.2
node-labels: "rack=rack0"
- role: worker
kubeadmConfigPatches:
- |
kind: JoinConfiguration
nodeRegistration:
kubeletExtraArgs:
node-ip: 10.0.3.2
node-labels: "rack=rack1"
- role: worker
kubeadmConfigPatches:
- |
kind: JoinConfiguration
nodeRegistration:
kubeletExtraArgs:
node-ip: 10.0.4.2
node-labels: "rack=rack1"
|
执行以下命令,通过 Kind 创建 Kubernetes 集群。
1
| kind create cluster --config cluster.yaml
|
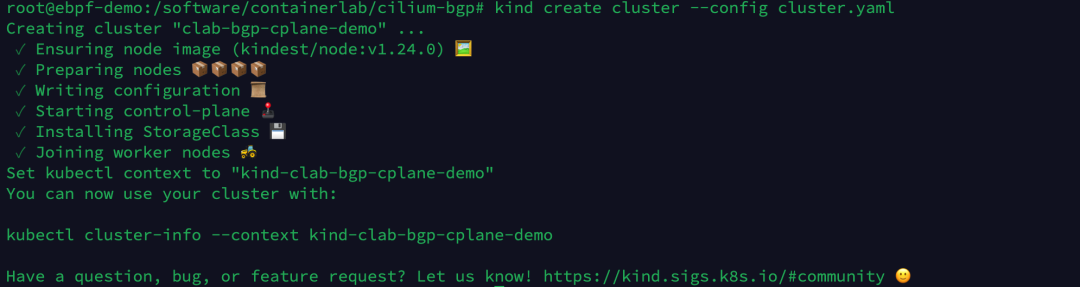
查看集群节点状态,由于当前我们尚未安装 CNI 插件,因此节点的状态是 NotReady。

4 启动 Containerlab
定义 Containerlab 的配置文件,创建网络基础设施并连接 Kind 创建的 Kubernetes 集群:
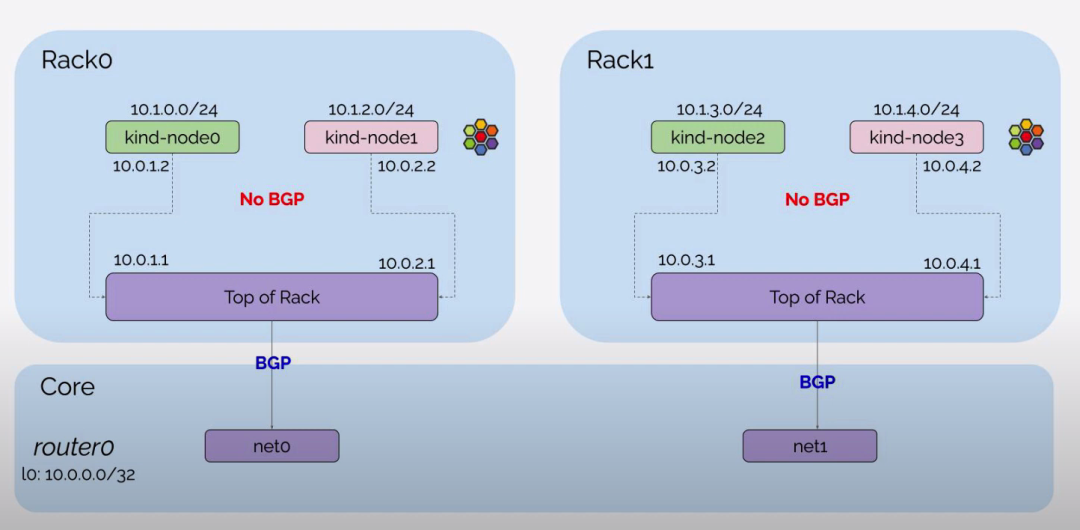
- router0, tor0, tor1 作为 Kubernetes 集群外部的网络设备,在 exec 参数中设置网络接口信息以及 BGP 配置。router0 与 tor0, tor1 建立 BGP 邻居,tor0 与 server0, server1, router0 建立 BGP 邻居,tor1 与 server2, server3, router0 建立 BGP 邻居。
- 设置
network-mode: container:<容器名> 可以让 Containerlab 共享 Containerlab 之外启动的容器的网络命名空间,设置 server0, server1, server2, server3 容器分别连接到第 3 小节中通过 Kind 创建的 Kubernetes 集群的 4 个 Node 上。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
|
name: bgp-cplane-demo
topology:
kinds:
linux:
cmd: bash
nodes:
router0:
kind: linux
image: frrouting/frr\:v8.2.2
labels:
app: frr
exec:
\- iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE
\- ip addr add 10.0.0.0/32 dev lo
\- ip route add blackhole 10.0.0.0/8
\- touch /etc/frr/vtysh.conf
\- sed -i -e 's/bgpd=no/bgpd=yes/g' /etc/frr/daemons
\- usr/lib/frr/frrinit.sh start
\- >-
vtysh -c 'conf t'
\-c 'router bgp 65000'
\-c ' bgp router-id 10.0.0.0'
\-c ' no bgp ebgp-requires-policy'
\-c ' neighbor ROUTERS peer-group'
\-c ' neighbor ROUTERS remote-as external'
\-c ' neighbor ROUTERS default-originate'
\-c ' neighbor net0 interface peer-group ROUTERS'
\-c ' neighbor net1 interface peer-group ROUTERS'
\-c ' address-family ipv4 unicast'
\-c ' redistribute connected'
\-c ' exit-address-family'
\-c '!'
tor0:
kind: linux
image: frrouting/frr:v8.2.2
labels:
app: frr
exec:
- ip link del eth0
- ip addr add 10.0.0.1/32 dev lo
- ip addr add 10.0.1.1/24 dev net1
- ip addr add 10.0.2.1/24 dev net2
- touch /etc/frr/vtysh.conf
- sed -i -e 's/bgpd=no/bgpd=yes/g' /etc/frr/daemons
- /usr/lib/frr/frrinit.sh start
- >-
vtysh -c 'conf t'
-c 'frr defaults datacenter'
-c 'router bgp 65010'
-c ' bgp router-id 10.0.0.1'
-c ' no bgp ebgp-requires-policy'
-c ' neighbor ROUTERS peer-group'
-c ' neighbor ROUTERS remote-as external'
-c ' neighbor SERVERS peer-group'
-c ' neighbor SERVERS remote-as internal'
-c ' neighbor net0 interface peer-group ROUTERS'
-c ' neighbor 10.0.1.2 peer-group SERVERS'
-c ' neighbor 10.0.2.2 peer-group SERVERS'
-c ' address-family ipv4 unicast'
-c ' redistribute connected'
-c ' exit-address-family'
-c '!'
tor1:
kind: linux
image: frrouting/frr:v8.2.2
labels:
app: frr
exec:
- ip link del eth0
- ip addr add 10.0.0.2/32 dev lo
- ip addr add 10.0.3.1/24 dev net1
- ip addr add 10.0.4.1/24 dev net2
- touch /etc/frr/vtysh.conf
- sed -i -e 's/bgpd=no/bgpd=yes/g' /etc/frr/daemons
- /usr/lib/frr/frrinit.sh start
- >-
vtysh -c 'conf t'
-c 'frr defaults datacenter'
-c 'router bgp 65011'
-c ' bgp router-id 10.0.0.2'
-c ' no bgp ebgp-requires-policy'
-c ' neighbor ROUTERS peer-group'
-c ' neighbor ROUTERS remote-as external'
-c ' neighbor SERVERS peer-group'
-c ' neighbor SERVERS remote-as internal'
-c ' neighbor net0 interface peer-group ROUTERS'
-c ' neighbor 10.0.3.2 peer-group SERVERS'
-c ' neighbor 10.0.4.2 peer-group SERVERS'
-c ' address-family ipv4 unicast'
-c ' redistribute connected'
-c ' exit-address-family'
-c '!'
server0:
kind: linux
image: nicolaka/netshoot:latest
network-mode: container:control-plane
exec:
- ip addr add 10.0.1.2/24 dev net0
- ip route replace default via 10.0.1.1
server1:
kind: linux
image: nicolaka/netshoot:latest
network-mode: container:worker
exec:
- ip addr add 10.0.2.2/24 dev net0
- ip route replace default via 10.0.2.1
server2:
kind: linux
image: nicolaka/netshoot:latest
network-mode: container:worker2
exec:
- ip addr add 10.0.3.2/24 dev net0
- ip route replace default via 10.0.3.1
server3:
kind: linux
image: nicolaka/netshoot:latest
network-mode: container:worker3
exec:
- ip addr add 10.0.4.2/24 dev net0
- ip route replace default via 10.0.4.1
links:
* endpoints: \["router0\:net0", "tor0\:net0"]
* endpoints: \["router0\:net1", "tor1\:net0"]
* endpoints: \["tor0\:net1", "server0\:net0"]
* endpoints: \["tor0\:net2", "server1\:net0"]
* endpoints: \["tor1\:net1", "server2\:net0"]
* endpoints: \["tor1\:net2", "server3\:net0"]
|
执行以下命令,创建 Containerlab 实验环境。
1
| clab deploy -t topo.yaml
|
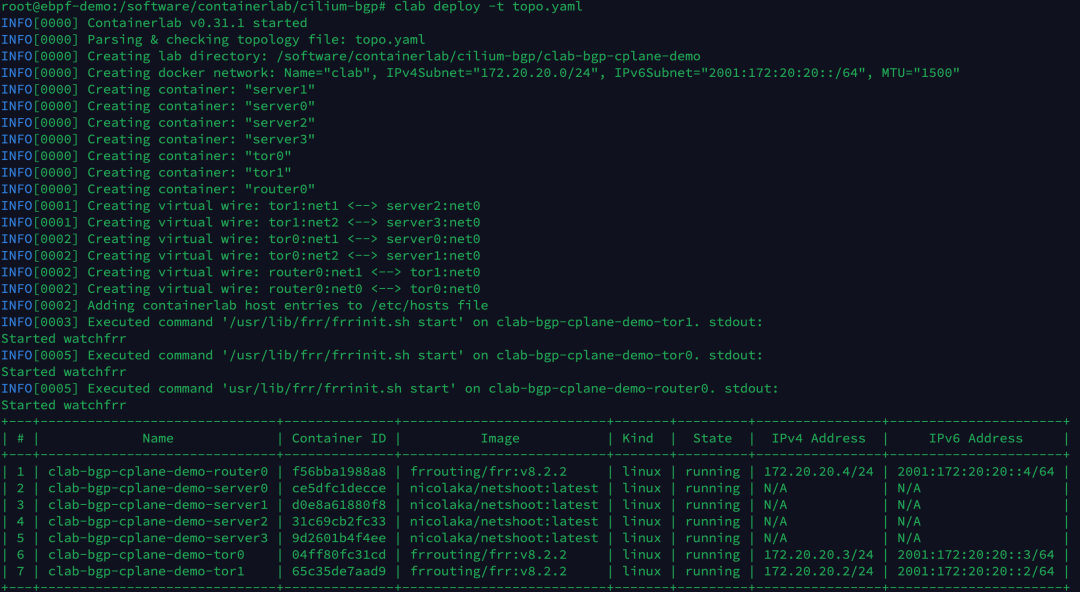
创建完的拓扑如下所示,当前只有 tor0, tor1 和 router0 设备之间建立了 BGP 连接,由于我们尚未通过 CiliumBGPPeeringPolicy 设置 Kubernetes 集群的 BGP 配置,因此 tor0, tor1 与 Kubernetes Node 的 BGP 连接还没有建立。
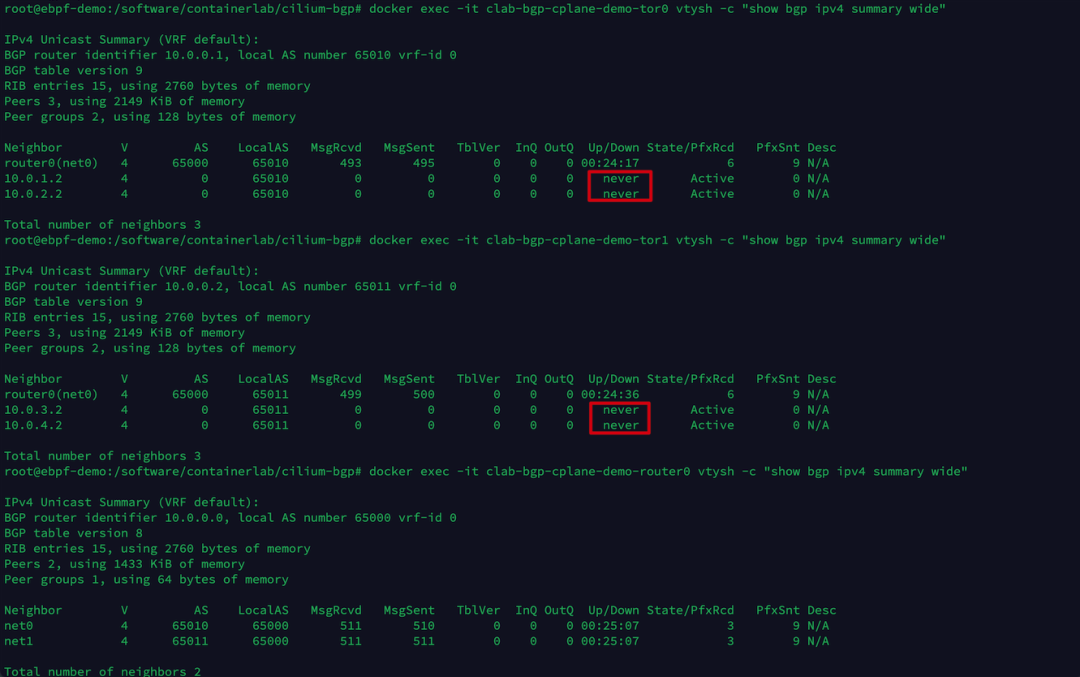
分别执行以下命令,可以查看 tor0, tor1, router0 3 个网络设备当前的 BGP 邻居建立情况。
1
2
3
| docker exec -it clab-bgp-cplane-demo-tor0 vtysh -c "show bgp ipv4 summary wide"
docker exec -it clab-bgp-cplane-demo-tor1 vtysh -c "show bgp ipv4 summary wide"
docker exec -it clab-bgp-cplane-demo-router0 vtysh -c "show bgp ipv4 summary wide"
|
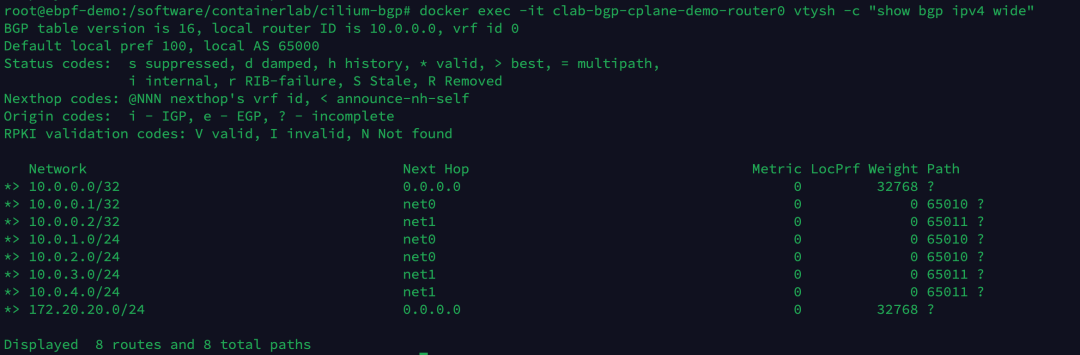
执行以下命令,查看 router0 设备现在学到的 BGP 路由条目。
1
| docker exec -it clab-bgp-cplane-demo-router0 vtysh -c "show bgp ipv4 wide"
|
当前总共有 8 条路由条目,此时还未学到 Pod 相关的路由。
为了方便用户更直观地了解实验的网络结构,Containerlab 提供 graph 命令生成网络拓扑。

在浏览器输入 http://<宿主机 IP>:50080 可以查看 Containerlab 生成的拓扑图。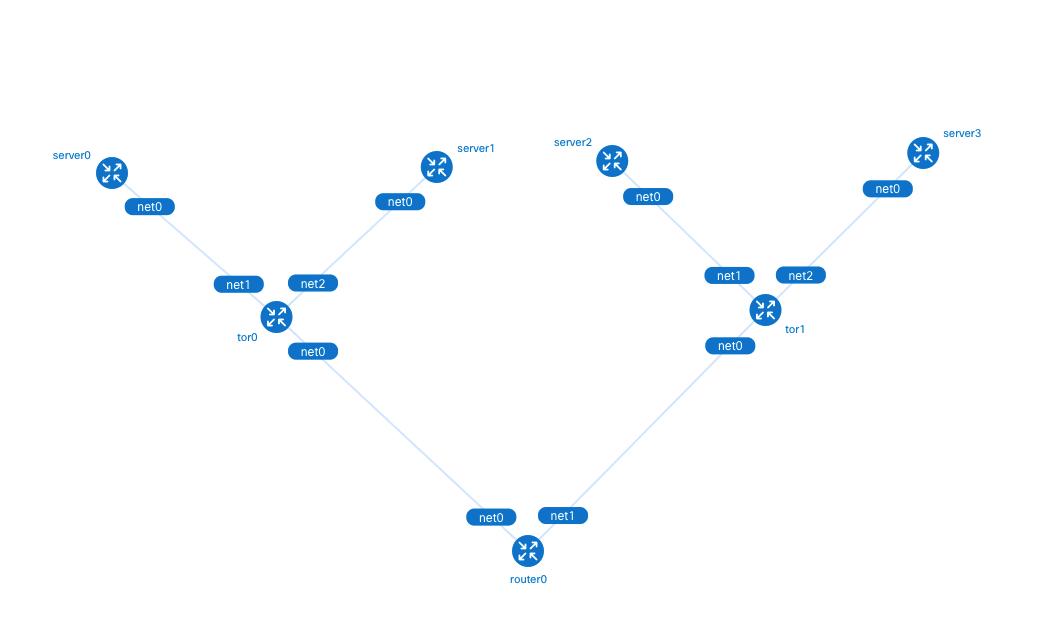
5 安装 Cilium
本例中使用 Helm 来安装 Cilium,在 values.yaml 配置文件中设置我们需要调整的 Cilium 配置参数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
tunnel: disabled
ipam:
mode: kubernetes
ipv4NativeRoutingCIDR: 10.0.0.0/8
bgpControlPlane:
enabled: true
k8s:
requireIPv4PodCIDR: true
|
执行以下命令,安装 Cilium 1.12 版本,开启 BGP 功能支持。
1
2
| helm repo add cilium https://helm.cilium.io/
helm install -n kube-system cilium cilium/cilium --version v1.12.1 -f values.yaml
|
等待所有 Cilium Pod 启动完毕后,再次查看 Kubernetes Node 状态,可以看到所有 Node 都已经处于 Ready 状态了。

6 Cilium 节点配置 BGP
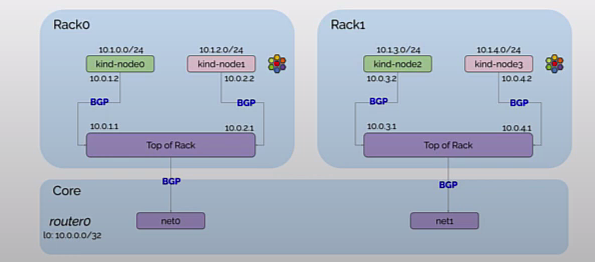
接下来分别为 rack0 和 rack1 两个机架上 Kubernetes Node 配置 CiliumBGPPeeringPolicy。rack0 和 rack1 分别对应 Node 的 label,在第 3 小节中 Kind 的配置文件中做过设置。
rack0 的 Node 与 tor0 建立 BGP 邻居,rack1 的 Node 与 tor1 建立 BGP 邻居,并自动宣告 Pod CIDR 给 BGP 邻居。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
apiVersion: "cilium.io/v2alpha1"
kind: CiliumBGPPeeringPolicy
metadata:
name: rack0
spec:
nodeSelector:
matchLabels:
rack: rack0
virtualRouters:
- localASN: 65010
exportPodCIDR: true
neighbors:
- peerAddress: "10.0.0.1/32"
peerASN: 65010
---
apiVersion: "cilium.io/v2alpha1"
kind: CiliumBGPPeeringPolicy
metadata:
name: rack1
spec:
nodeSelector:
matchLabels:
rack: rack1
virtualRouters:
- localASN: 65011
exportPodCIDR: true
neighbors:
- peerAddress: "10.0.0.2/32"
peerASN: 65011
|
执行以下命令,应用 CiliumBGPPeeringPolicy。
1
| kubectl apply -f cilium-bgp-peering-policies.yaml
|
创建完的拓扑如下所示,现在 tor0 和 tor1 也已经和 Kubernetes Node 建立了 BGP 邻居。
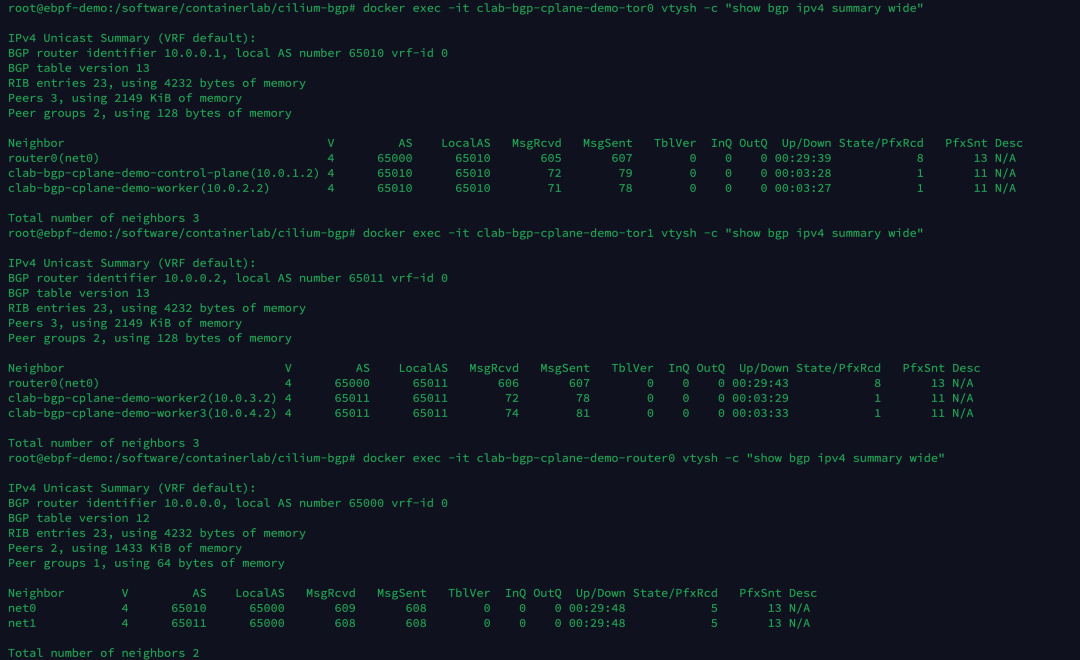
分别执行以下命令,可以查看 tor0, tor1, router0 3 个网络设备当前的 BGP 邻居建立情况。
1
2
3
| docker exec -it clab-bgp-cplane-demo-tor0 vtysh -c "show bgp ipv4 summary wide"
docker exec -it clab-bgp-cplane-demo-tor1 vtysh -c "show bgp ipv4 summary wide"
docker exec -it clab-bgp-cplane-demo-router0 vtysh -c "show bgp ipv4 summary wide"
|
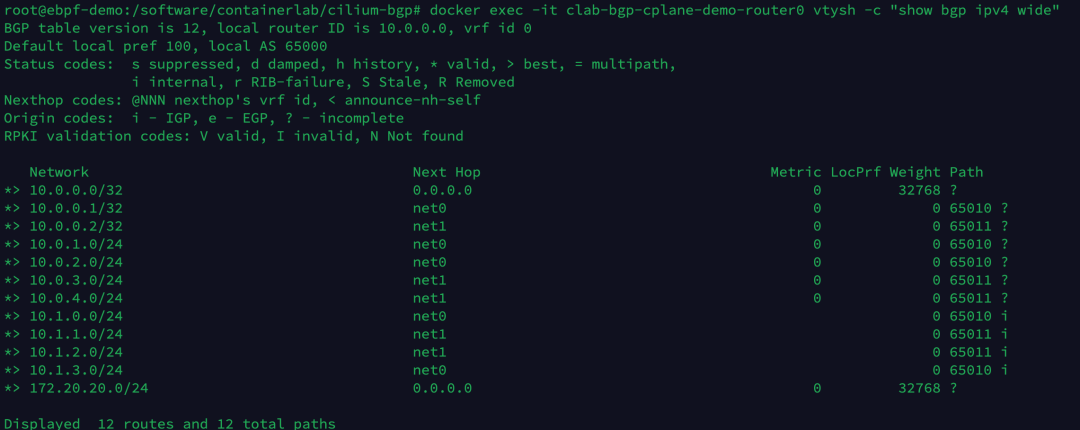
执行以下命令,查看 router0 设备现在学到的 BGP 路由条目。
1
| docker exec -it clab-bgp-cplane-demo-router0 vtysh -c "show bgp ipv4 wide"
|
当前总共有 12 条路由条目,其中多出来的 4 条路由是从 Kubernetes 4 个 Node 学到的 10.1.x.0/24 网段的路由。
7 验证测试
分别在 rack0 和 rack1 所在的节点上创建 1 个 Pod 用于测试网络的连通性。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
apiVersion: v1
kind: Pod
metadata:
labels:
run: nettool-1
name: nettool-1
spec:
containers:
- image: cr7258/nettool:v1
name: nettool-1
nodeSelector:
rack: rack0
---
apiVersion: v1
kind: Pod
metadata:
labels:
run: nettool-2
name: nettool-2
spec:
containers:
- image: cr7258/nettool:v1
name: nettool-2
nodeSelector:
rack: rack1
|
执行以下命令,创建 2 个测试 Pod。
1
| kubectl apply -f nettool.yaml
|
查看 Pod 的 IP 地址。
nettool-1 Pod 位于 clab-bgp-cplane-demo-worker(server1, rack0)上,IP 地址是 10.1.2.185;nettool-2 Pod 位于 clab-bgp-cplane-demo-worker3(server3, rack1) 上,IP 地址是 10.1.3.56。

执行以下命令,在 nettool-1 Pod 中尝试 ping nettool-2 Pod。
1
| kubectl exec -it nettool-1 -- ping 10.1.3.56
|
可以看到 nettool-1 Pod 能够正常访问 nettool-2 Pod。

接下来使用 traceroute 命令观察网络数据包的走向。
1
| kubectl exec -it nettool-1 -- traceroute -n 10.1.3.56
|

数据包从 nettool-1 Pod 发出,依次经过了:
1.server1 的 cilium_host 接口:Cilium 网络中 Pod 的默认路由指向了本机的 cilium_host。cilium_host 和cilium_net 是一对 veth pair 设备。Cilium 通过 hardcode ARP 表,强制将 Pod 流量的下一跳劫持到 veth pair 的主机端。


2.tor0 的 net2 接口。
3.router0 的 lo0 接口:tor0, tor1 和 router0 3 个网络设备间通过本地环回口 lo0 建立 BGP 邻居,这样做可以在有多条物理链路备份的情况下提升 BGP 邻居的稳健性,不会因为某个物理接口故障时而影响到邻居关系。
4.tor1 的 lo0 接口。
5.server3 的 net0 接口。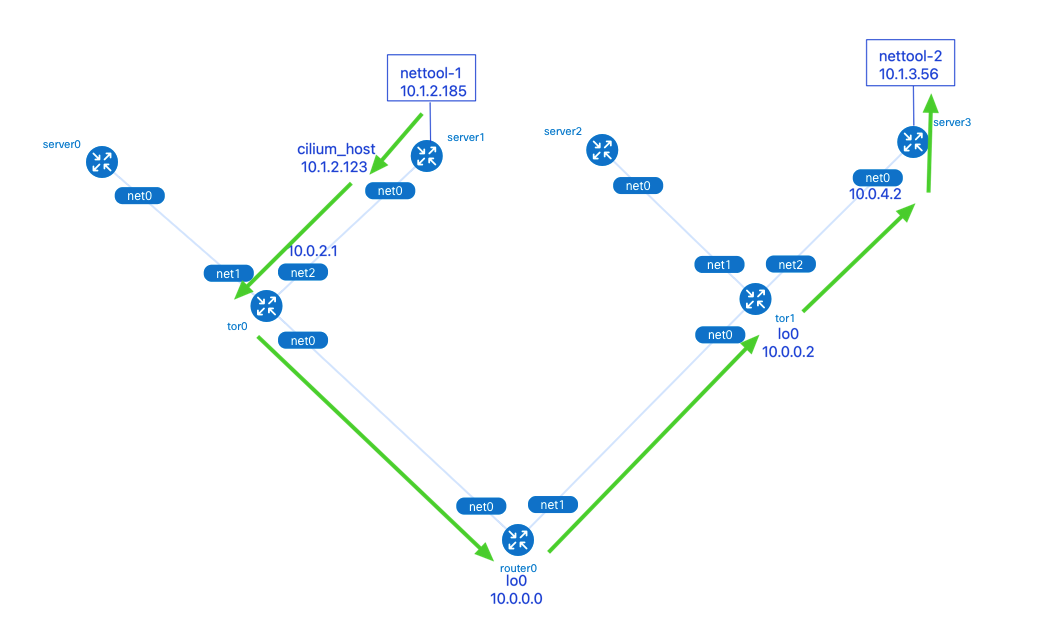
8 清理环境
执行以下命令,清理 Containerlab 和 Kind 创建的实验环境。
1
2
| clab destroy -t topo.yaml
kind delete clusters clab-bgp-cplane-demo
|