Prometheus 自定义告警规则
一、概述
通过创建 Prometheus 监控告警规则,您可以制定针对特定 Prometheus 实例的告警规则。当告警规则设置的条件满足后,系统会产生对应的告警事件。如果想要收到通知,需要进一步配置对应的通知策略以生成告警并且以短信、邮件、电话、钉群机器人、企业微信机器人或者 Webhook 等方式发送通知。
从 Prometheus server 端接收到 alerts 后,会基于 PromQL 的告警规则 分析数据,如果满足 PromQL 定义的规则,则会产生一条告警,并发送告警信息到 Alertmanager,Alertmanager 则是根据配置处理告警信息并发送。所以 Prometheus 的告警配置依赖于PromQL与AlertManager,关于这两个介绍可以参考以下文章:
- Prometheus AlertManager 实战[1]
- Prometheus PromQL 实战[2]
- Prometheus Pushgetway 实战[3]
- 官方文档
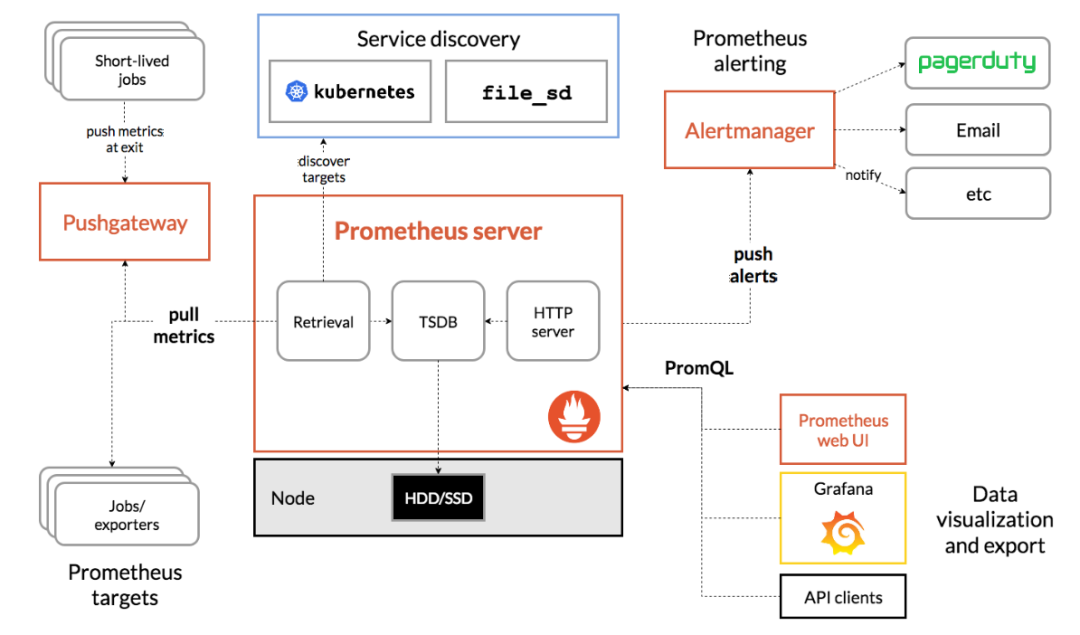
二、告警实现流程
设置警报和通知的主要步骤是:
- 在 Prometheus 中配置告警规则。
- 配置 Prometheus 与 AlertManager 关联。
- 配置 AlertManager 告警通道。
三、告警规则
1)告警规则配置
在 Prometheus 配置(prometheus.yml)中添加报警规则配置,配置文件中 rule_files 就是用来指定报警规则文件的,如下配置即指定存放报警规则的目录为/etc/prometheus,规则文件为 rules.yml:
1 | rule_files: |
设置报警规则:
警报规则允许基于 Prometheus 表达式语言的表达式来定义报警报条件的,并在触发警报时发送通知给外部的接收者(Alertmanager),一条警报规则主要由以下几部分组成:
alert——告警规则的名称。expr——是用于进行报警规则 PromQL 查询语句。for——评估告警的等待时间(Pending Duration)。labels——自定义标签,允许用户指定额外的标签列表,把它们附加在告警上。annotations——用于存储一些额外的信息,用于报警信息的展示之类的。
rules.yml 示例如下:
1 | groups: |
1)监控服务器是否在线
对于被 Prometheus 监控的服务器,我们都有一个 up 指标,可以知道该服务是否在线。
1 | up == 0 #服务下线了。 |
【示例】
1 | groups: |
注意:
for指定达到告警阈值之后,一致要持续多长时间,才发送告警数据。labels中可以指定自定义的标签,如果定义的标签已经存在,则会被覆盖。可以使用模板。annotations中的数据,可以使用模板,$labels表示告警数据的标签,{{$value}}表示时间序列的值。
3)告警数据的状态
Inactive——表示没有达到告警的阈值,即 expr 表达式不成立。Pending——表示达到了告警的阈值,即 expr 表达式成立了,但是未满足告警的持续时间,即 for 的值。Firing——已经达到阈值,且满足了告警的持续时间。
【温馨提示】经测试发现,如果同一个告警数据达到了 Firing,那么不会再次产生一个告警数据,除非该告警解决了。
四、实战操作
1)下载 node_exporter
node-exporter 用于采集 node 的运行指标,包括 node 的 cpu、load、filesystem、meminfo、network 等基础监控指标,类似于 zabbix 监控系统的的 zabbix-agent。
1 | wget https://github.com/prometheus/node_exporter/releases/download/v1.5.0/node_exporter-1.5.0.linux-amd64.tar.gz |
2)启动 node_exporter
1 | ln -s /opt/prometheus/exporter/node_exporter/node_exporter-1.5.0.linux-amd64/node_exporter /usr/local/bin/node_exporter |
配置node_exporter.service启动
1 | # 默认端口9100 |
启动服务
1 | systemctl daemon-reload |
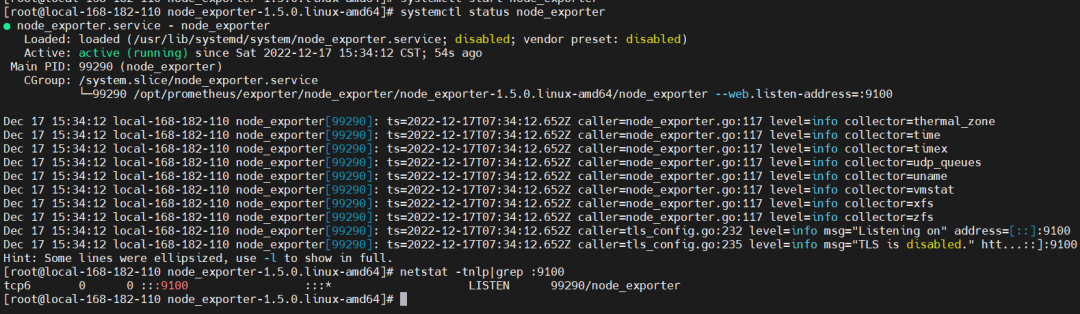 检查
检查
1 | curl http://localhost:9100/metrics |
3)配置 Prometheus 加载 node_exporter
添加或修改配置 prometheus.yml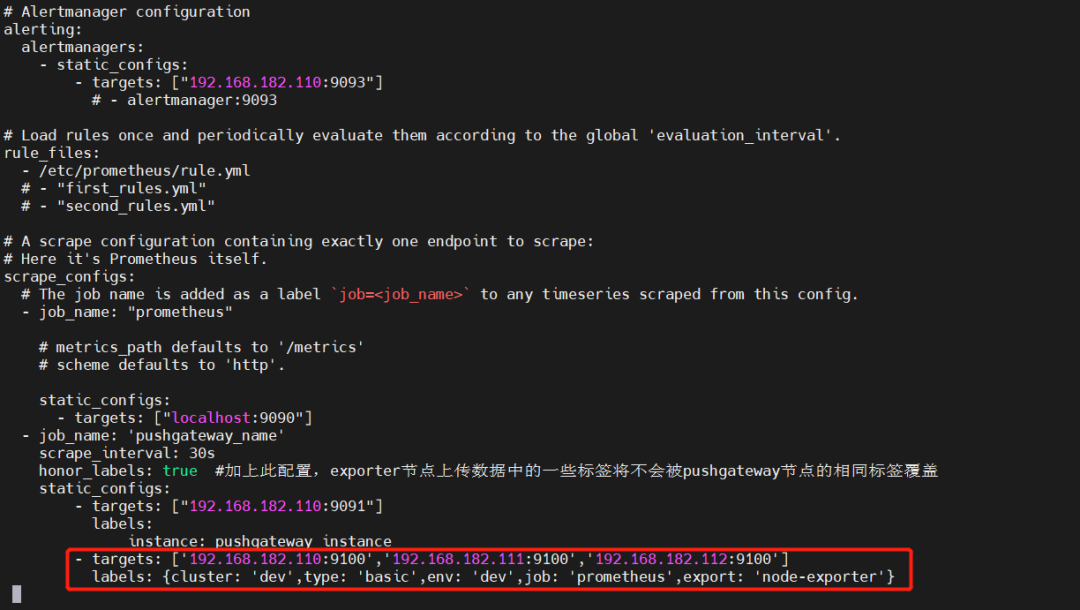
重启加载配置
1 | systemctl restart prometheus |
检查
web:http://ip:9090/targets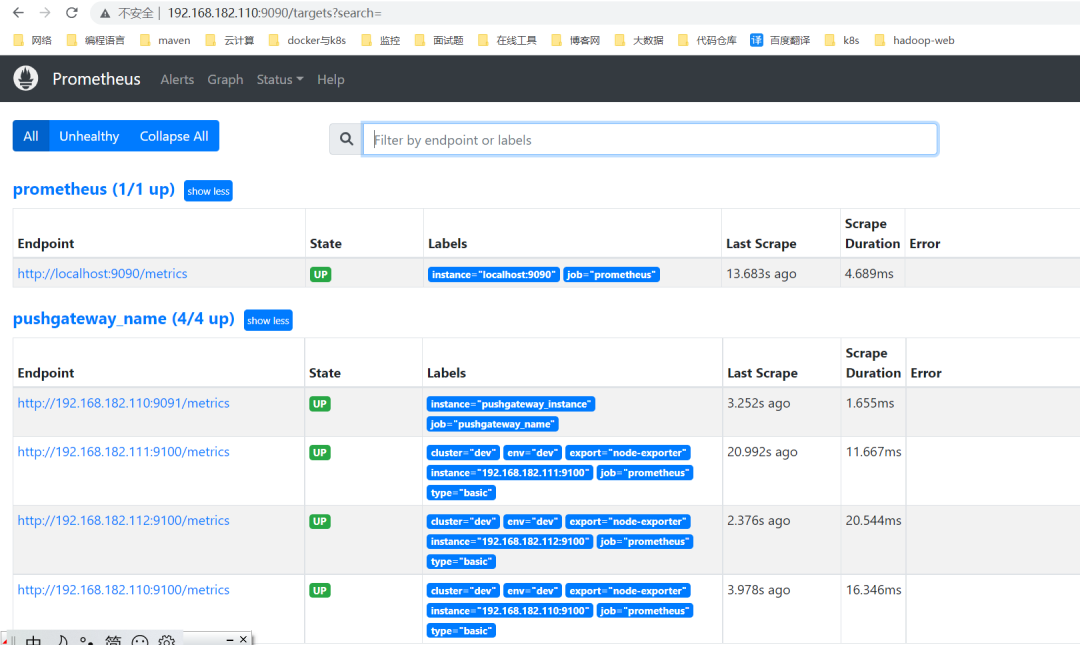
4)告警规则配置
在 Prometheus 配置文件rometheus.yml 中配置如下: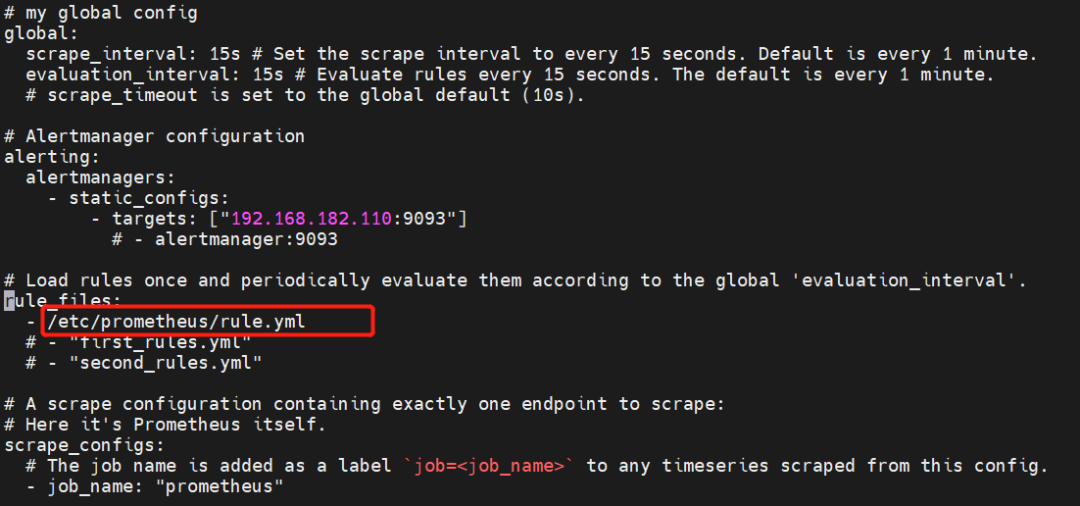
在/etc/prometheus/rule.yml配置如下:
1 | groups: |
重新加载
1 | curl -X POST http://localhost:9090/-/reload |
在 web 上就可以看到一个告警规则。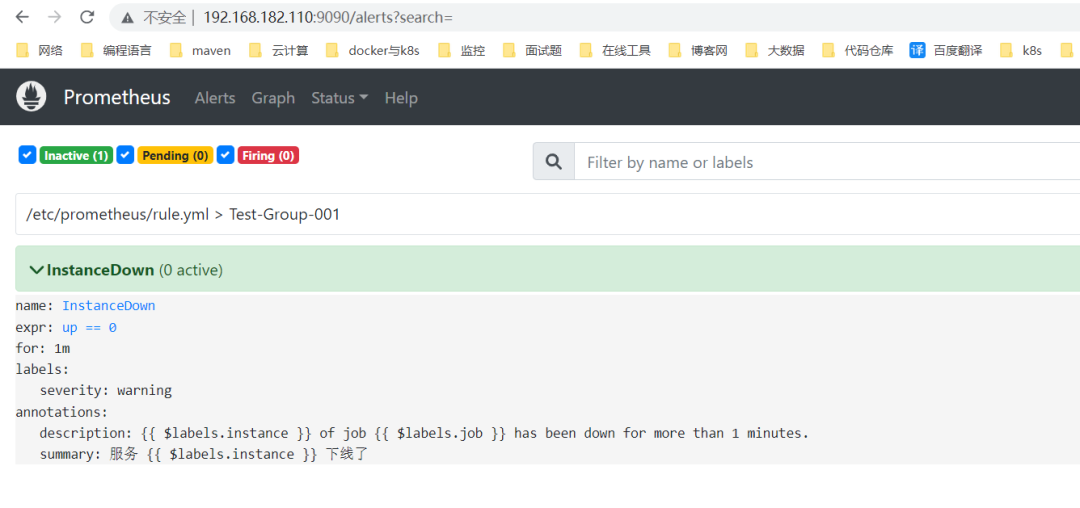
5)模拟告警
手动关机
1 | sudo shutdown -h now |
过了一段时间告警状态就变成Pending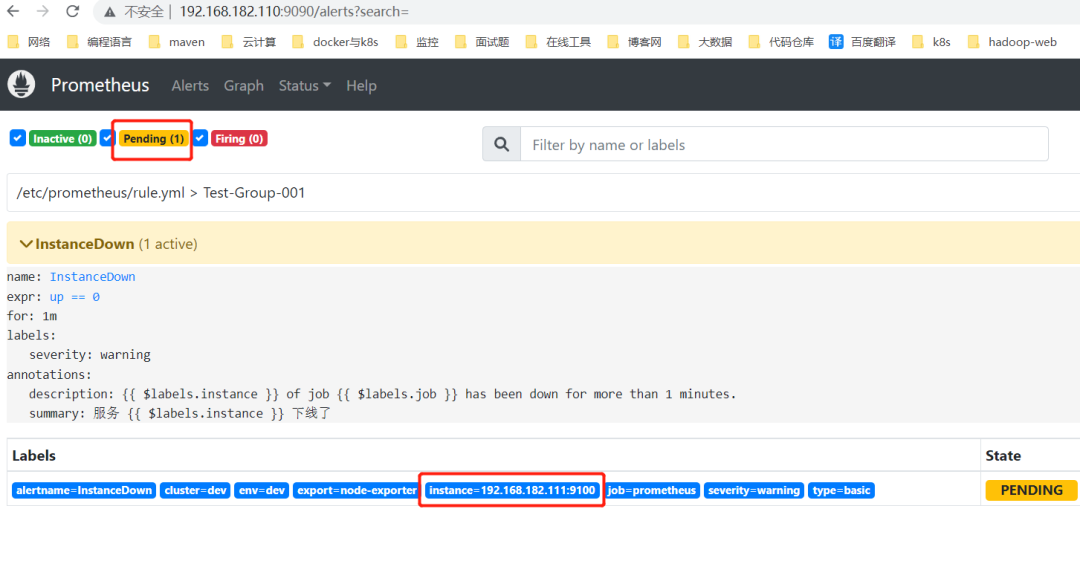
再过一段时间告警就变成了Firing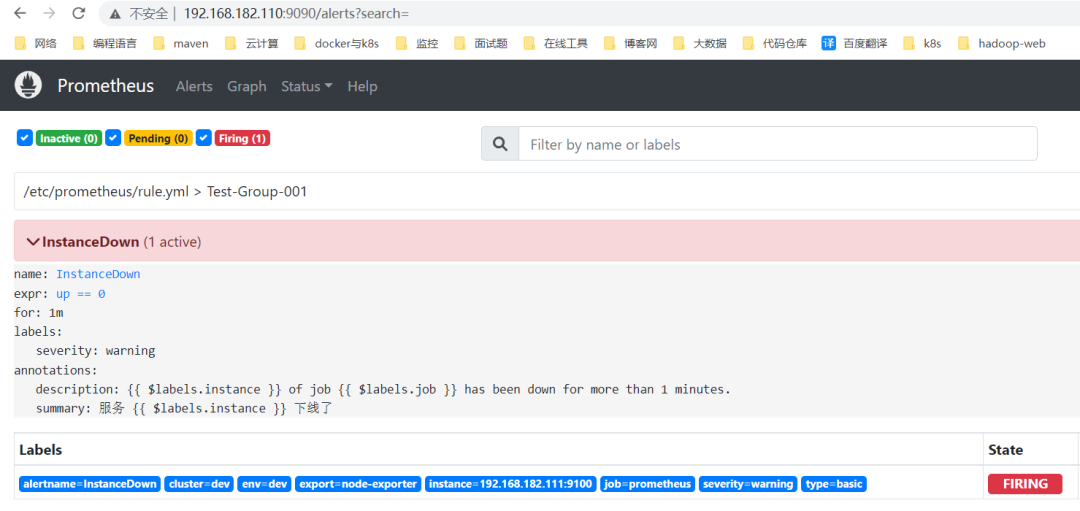
6)配置告警通道
这里以有邮件告警为示例,其它的也差不多。修改配置之前最好先备份一下之前的配置
1 | cp alertmanager.yml alertmanager.bak |
【1】配置 alertmanager.yml
1 | global: |
【2】模板 alert.tmpl
模板文件配置了email.from、email.to、email.to.html 三种模板变量,可以在 alertmanager.yml 文件中直接配置引用。这里 email.to.html 就是要发送的邮件内容,支持 Html 和 Text 格式,这里为了显示好看,采用 Html 格式简单显示信息。下边 是个循环语法,用于循环获取匹配的 Alerts 的信息。
1 | {{ define "email.from" }}xxxxxxxx@qq.com{{ end }} |
【温馨提示】这里记得换成自己的邮箱地址!!!
重启 alertmanager
1 | systemctl restart alertmanager |
在 web 上就可以看到对应的告警信息了。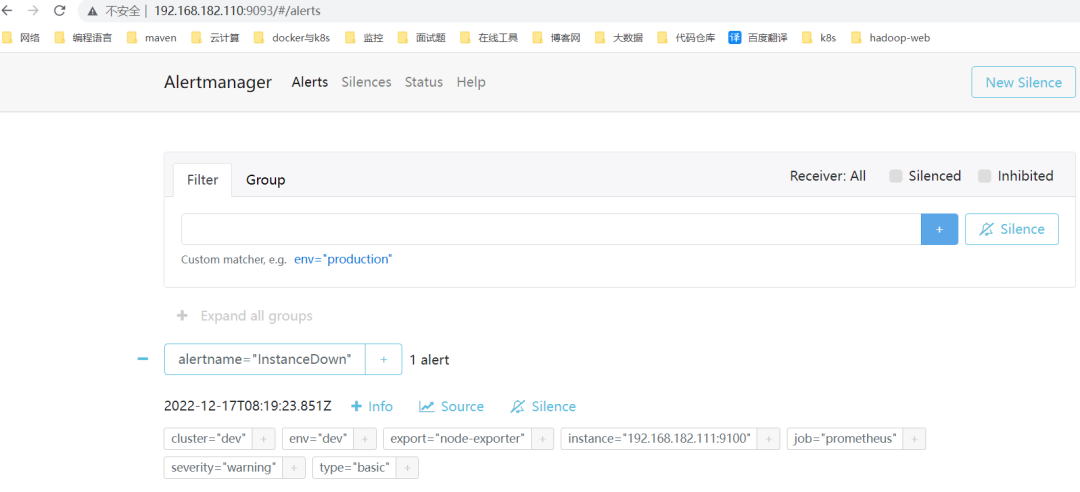
接下来就静待告警了。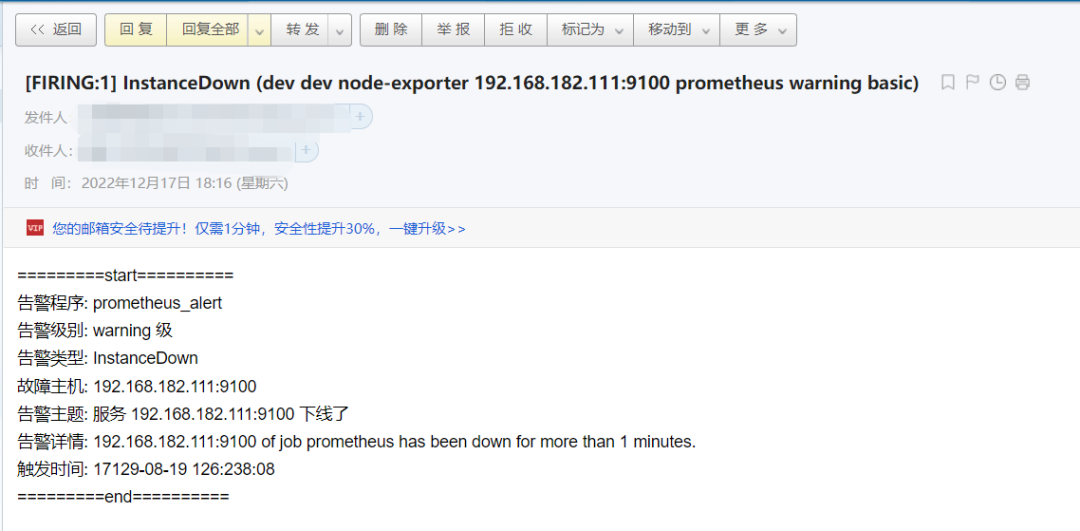
一整套流程到这里就全部跑通了,告警规则、告警指标、告警通道根据自己的场景来定
参考资料
[1] Prometheus AlertManager 实战
[2] Prometheus PromQL 实战
[3] Prometheus Pushgetway 实战