CubeFS助力ClickHouse存算分离
01.简介
ClickHouse是一个用于关系型联机分析(ROLAP)的列式数据库管理系统(DBMS),擅长PB级数据量的交互式分析。自2016 年开源以来,ClickHouse 凭借其数倍于业界顶尖分析型数据库的极致性能,成为交互式分析领域的后起之秀。
CubeFS,则独具创新的设计,与其他产品有较明显的区别:它支持水平扩展的强一致性的元数据服务,提供了副本数弹性可变的多副本存储以及可灵活编码的纠删码存储,此外还支持多级智能加速能力,支持标准S3、POSIX、HDFS三种访问协议,与K8S及容器生态亦有良好兼容性。作为CNCF首个国产开源存储产品,CubeFS吸引了众多社区用户及开发者参与共建,除在OPPO广泛使用外,也已在国内10余家头部企业如京东、网易、贝壳找房、360、魅族、LinkSure网络、Reconova的各个核心业务上落地;部分企业如OPPO、京东、网易、贝壳等使用CubeFS数据规模已达数十PB甚至百PB级。
02.为什么选择CubeFS
我们选择CubeFS做冷热分离有以下考虑:
- CubeFS提供了比较丰富的接口,支持S3协议, 也可以本地部署client或者嵌入SDK,当作本地盘使用。社区版ClickHouse很早就支持了S3来做冷热分离,并在此基础上,演进了 zero_copy能力,减少冷盘读写的放大。
- CubeFS是一款安全可靠、扩展性强、易于运维的云原生分布式存储,提供了文件及对象存储能力。作为CNCF首个国产开源存储产品(孵化阶段),有优秀人员参与社区贡献,已在国内外数十家头部公司的生产环境上经历实际业务锤炼。
- CubeFS有较为丰富的配置,能为不同业务配置不同性能。比如可以给选择不同存储类型的集群, SSD集群主打性能,带宽可以达到4GB/s以上,HDD集群主打性价比, 性能接近 SATA SSD,但价格便宜很多。同一个集群存储上可以配置单副本卷和多副本卷, 也可以配置EC卷来达成数据备份,并且 zone的概念也可以达成副本多机房的容灾能力。
- CubeFS可以支持多租户,并且有很好的租户隔离能力, 多个ClickHouse集群可以共享同一个CubeFS集群,方便维护。
而ClickHouse方面通过CubeFS设置的数据分层,也能够达成以下方面的优势:
- 超大容量:CubeFS提供了几乎无容量上限的存储空间,使ClickHouse的容量上限不再受本机资源限制。
- 更高的性价比:相对于本地SSD存储阵列,CubeFS通过集群多机IO并发,同等价格下,SSD集群提供了远超SSD阵列的带宽, 而HDD集群提供了接近SSD的性能,成本更低。
- 更高的稳定性:通过配置CubeFS冷盘后,将本地磁盘的带宽瓶颈转换成网卡的带宽瓶颈。网卡带宽要高于磁盘带宽很多,因此,采用CubeFS容器化后的ClickHouse受到同一物理机上其他容器影响更小。
03.冷热分离架构的演进
▎初识冷热分离
我们当前线上的版本是20.8和22.3, ClickHouse已经可以支持 multi-volume storage这个功能,它允许将ClickHouse定义自己的存储策略,存储策略可以指定多个 volume和多个 disk。建表时通过指定表的 storage_policy参数,来实现表级别存储策略。利用这个特性,我们可以很容易的指定一些表实现冷热分离,甚至存算分离。
以下是网站上关于 multi-volume storage的架构图。
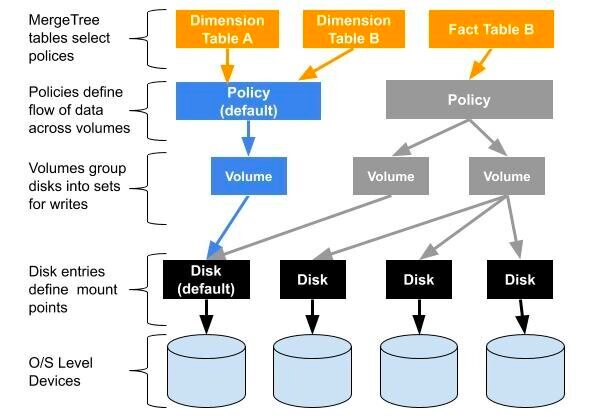
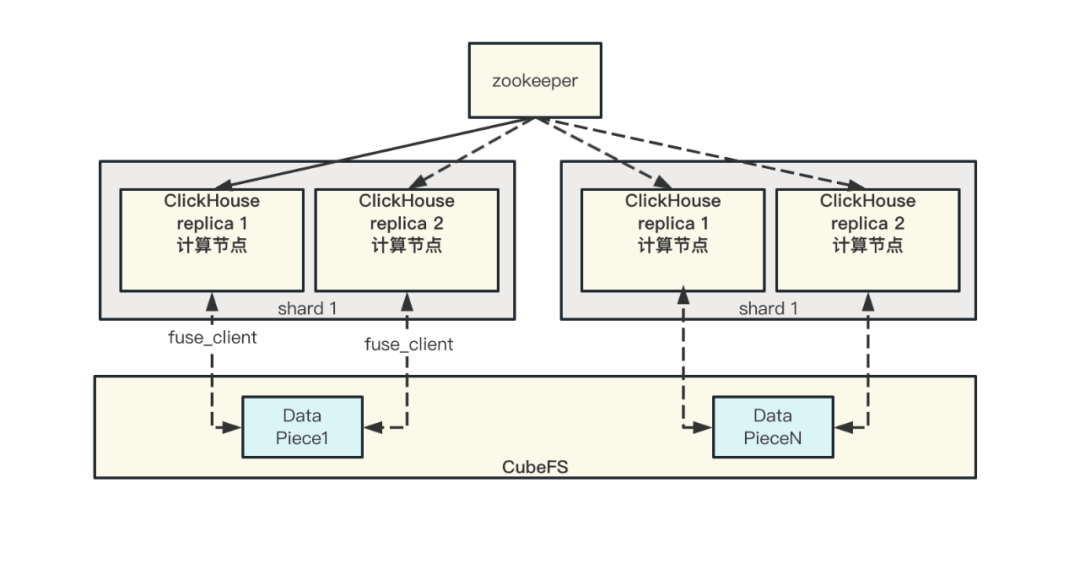
我们冷热分离的架构如下
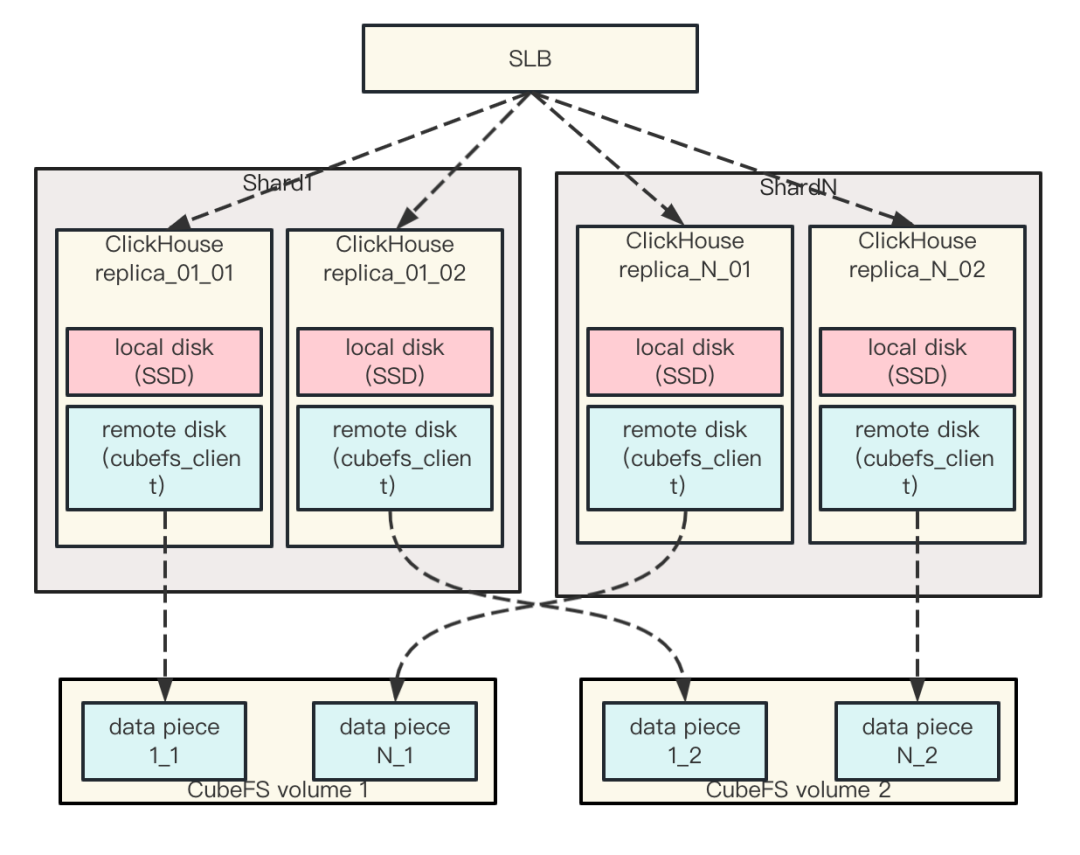
- 每个ClickHouse实例都配置有一份热盘、一份冷盘,ClickHouse实例之间没有数据共享
- ClickHouse集群同一个分片的不同副本实例使用不同的 CubeFS卷,以保证ClickHouse实例副本的数据不会部署到CubeFS集群下的同一台机器,从而达成容灾能力。
- 为了节约成本,冷数据都采用单副本存储。
我们ClickHouse集群一般采用双副本多分片的方式组织,也可以根据具体的业务需求配置三副本甚至更多。client通过SLB的下发策略将 query下发到对应的ClickHouse实例,ClickHouse 实例根据表指定的存储策略来进行数据读取。每个server端都有配置 cubefs_client用来连接到后端CubeFS存储。
冷数据这里我们都采用单副本存储,在容灾能力上,可以配置成同集群双卷或者不同集群不同卷。前者具备CubeFS集群出现部分节点故障的容灾能力,后者具有CubeFS出现集群整体故障的容灾能力,后者还可以将CubeFS集群部署在不同城市,达成多地域的容灾能力。
▎共享数据的冷热分离
尽管初步的冷热分离架构已经能够在生产上使用,但面对业务越来越高的稳定性要求, 当前方案也面临着不少问题:
- ClickHouse单机出现故障,可能导致数据丢失。
- 冷数据存储需要两个CubeFS集群,配置比较繁琐 ,如果配置一个集群又面临着cfs单副本批量坏盘的风险。
- 单副本架构下稳定性欠佳,CubeFS单副本出现问题之后,虽然CK可以切到正常的副本进行业务读取,但切换过程中的请求仍会出错。如果CubeFS发生批量坏盘故障, 也会导致一段时间有一个副本不可用,这也会增加CK集群的稳定性风险。
因此,我们在原有基础上开发了共享存储的架构
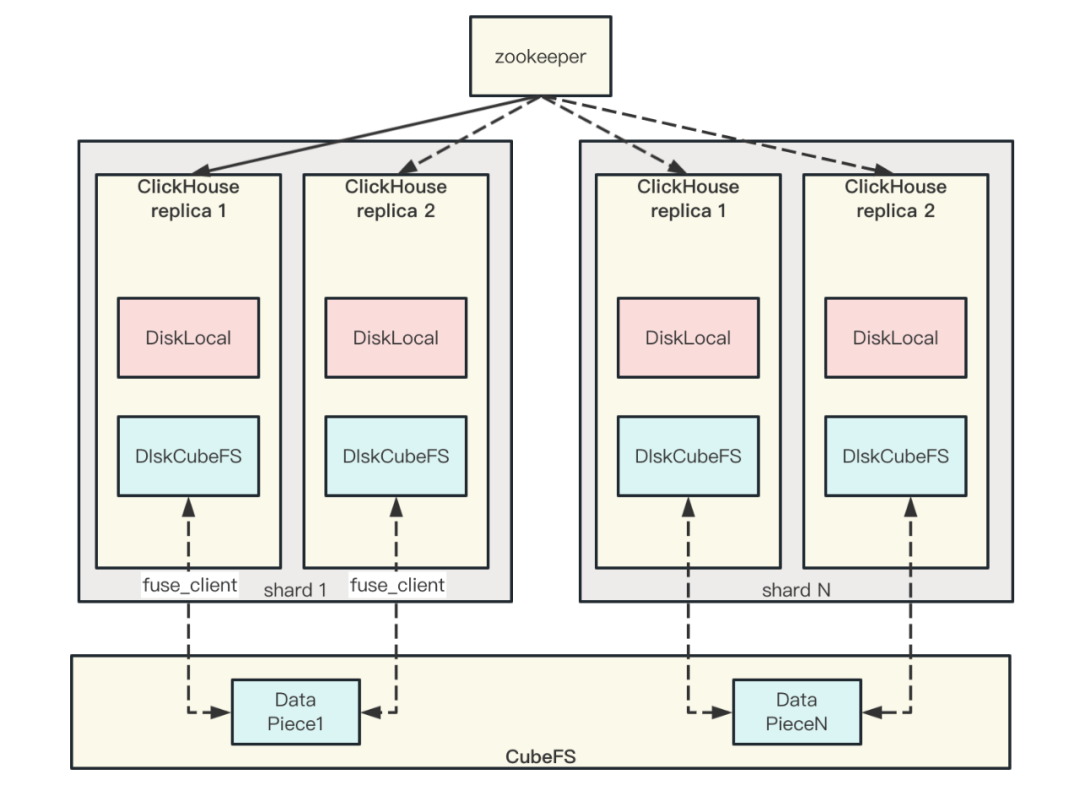
▎新框架的优势与不足
缺点:
新架构下,没有区分主从, 因此需要使用分布式锁来实现对同一份数据后台任务的互斥。目前这一块是通过ZK来实现的,相当于增加了ZK的压力。
优点:
数据因为共享,CubeFS可以采用EC卷, 理论上可以将热冷副本比例降低到1:0.75,进一步降低数据存储成本。当然EC卷本身也会带来一部分开销,这种只对部分场景适用。
冷数据采用CubeFS单一集群,配置起来更简单。
CubeFS可以根据需求配置成双副本或者三副本,和ClickHouse集群的副本数解藕, 也更容易配置存算分离。
稳定性更高。如果发生集群故障, 数据可以通过CubeFS自己的机制恢复, 不影响上层ClickHouse的数据读写, 也不需要ClickHouse运维介入到数据恢复。
▎存算分离演进
依托于数据共享的能力, 我们在此基础上,比较容易进一步演进成存算分离的架构。
存算分离因为面临着小文件的读取,因此,可以通过指定不同的存储策略来达成不同的效果。
利用TTL做数据搬迁的方式相当于本地盘做了cache,数据先落在本地合并一次之后才会迁移到CubeFS上。
直接指定冷盘,则数据完全写入到CubeFS集群, 因此还需要打开cfs冷盘的数据合并开关。这种方式虽然加大了CubeFS的性能开销,但也减少了ClickHouse后台数据搬迁的压力。
这两种方式可以分别对应不同的场景。小而快的数据写入用第一种比较合适, 而大批量的数据写入更适合用第二种。
04.配置冷热分离
▎本地挂载cfs磁盘
安装 fusermount
1 | wget https://ocs-cn-north1.heytapcs.com/cubefs/fusermount && chmod 755 fusermount && cp -f fusermount /usr/bin |
配置cfs客户端
1 | mkdir -p /home/service/app/cfs/ |
安装并启动cfs客户端, 执行之后就会自动挂在上/mnt/cfs目录
1 | mkdir -p /mnt/cfs |
创建ClickHouse实例冷盘目录, cfs 目录规则是 /mnt/cfs/集群名/副本名, 例如为test集群 replica_01_01副本创建目录
1 | mkdir -p /mnt/cfs/test/replica_01_01 |
▎ClickHouses配置冷热磁盘
在 config.d目录下(/home/service/app/clickhouse/config.d)增加ClickHouse关于 storage policies的配置文件 Storage.xml
当前我们的配置如下:
1 | <yandex> |
当前定义了两个盘:本地盘SSD和cfs盘。SSD作为热存储, cfs作为冷盘存储。
如要配置CFS数据共享的盘则需要更改磁盘类型成CubeFS, 因为数据要共享,因此同一shard的副本的cfs盘path配置相同。
1 | <yandex> |
配置说明
当前volumes没有指定 move_factor, 则默认 move_factor为0.1,即volume容量达到90%之后就会向下一个volume写入,避免volume爆满。
同时我们为冷盘配置了 prefer_not_to_merge, 避免冷盘数据的merge,造成不必要的性能浪费。
一个ClickHouse集群都会共用同一个CubeFS的卷, 我们通过path进行区分,path命令采用前缀+集群名+副本名的方式, 而共享数据模式下path要配置相同,一般采用前缀+集群名+shard分片号。
如果想默认现有的表都支持冷热分离,可以将 policies中的 hot_cold_separation名字改为default, ClickHouse默认表的存储策略就是default。
修改完配置文件之后,通过系统表 storage_policies就能看到新配置的磁盘策略。

▎创建冷热分离的表
建表语句举例,以mgbench的表schema举例
1 | CREATE TABLE if not exists mgbench.logs2 |
我们通过SETTINGS storage_policy 来指定表的存储策略,通过TTL语句来达成数据的冷热分离。
1 | TTL toDateTime(toUnixTimestamp(timestamp)) + toIntervalDay(30), toDateTime(toUnixTimestamp(timestamp)) + toIntervalDay(3) TO VOLUME 'cold' |
即数据只保留30天, 三天前的数据都存放到冷盘上。
▎演变成存算分离
当我们要实现存算分离时,也很简单,基于TTL规则,直接指定数据存放在cold即可。需要注意的是,新写入的data part很小,需要打开冷盘的merge功能, 即去掉prefer_not_to_merge选项。
1 | TTL toDateTime(toUnixTimestamp(timestamp)) + toIntervalDay(30), toDateTime(toUnixTimestamp(timestamp)) TO VOLUME 'cold' |
除此之外,也可以定义新的 storage_policy, 这种方式不依赖表本身的TTL特性, 但也少了本地盘做cache的能力。
1 | <yandex> |
建表语句指定存储策略和UUID即可
ClickHouse表不指定UUID, 在不同副本上可能使用不同的UUID, 在共享模式下,造成两副本实际存储在CubeFS上的路径不一样。我们建表指定UUID,为了多副本在共享模式下,使用同一CubeFS存储路径。
1 | CREATE TABLE if not exists mgbench.logs2 UUID 'fda38507-8fd4-45fa-8daa-1e37069da3ab'( |
05.冷热分离之后的性能对比
我们申请了1GB带宽的HDD CubeFS集群和4GB的SSD CubeFS与本地SSD磁盘阵列来进行性能对比。
▎带宽对比
为了更直观的对比CubeFS和SSD的性能, 我们简化了测试的模型。
分别创建两个表
1 | create table A(a Int64, timestamp Timestamp) Engine=MergeTree order by a; |
表A采用SSD存储,表B采用CubeFS存储, 我们向其中写入1亿条数据
1 | insert into A select *, now() from system.numbers limit 100000000; |
读取数据前10000行
1 | select * from A order by timestamp limit 10000; |
测试结果如下
读取数据量 100.00 million rows 读取数据大小 1.20GB
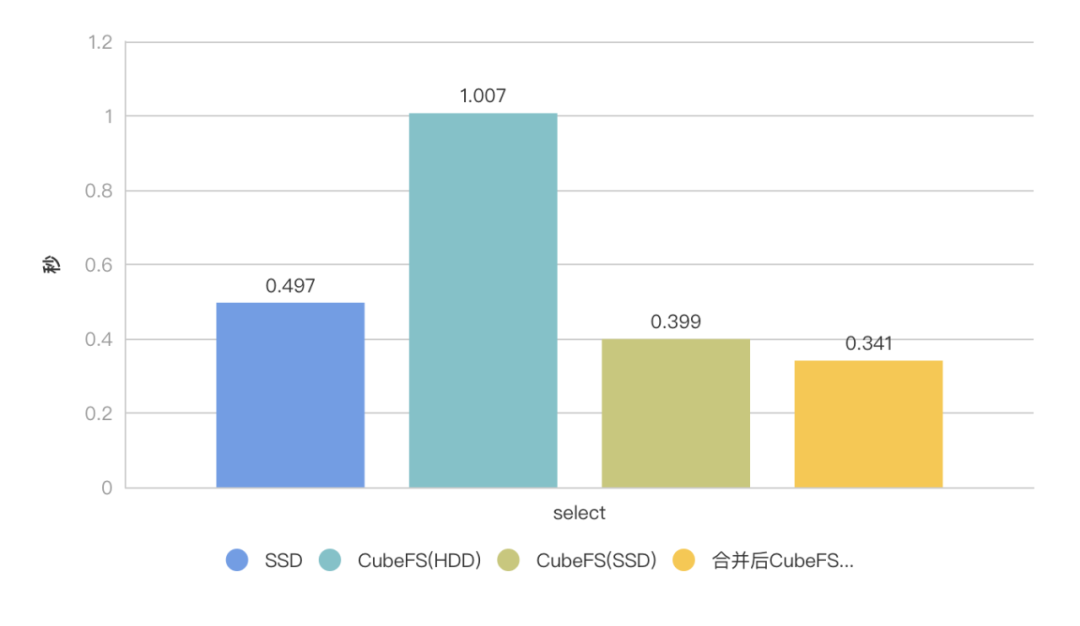
由此可见CubeFS文件读取性能还可以,HDD集群基本可以到达达到本地SSD磁盘阵列的49%的性能。而CubeFS SSD 集群小文件读取则达到了3GB/s,用时0.399s更是低于SSD阵列的0.497s,性能提升30%, CubeFS 小文件合并之后读,性能进一步提高,用时低至0.341s。
▎延迟对比
延迟对比我们仿造正常的业务查询, 采用官网mgbench的数据来进行对比, 相关的数据下载及对应query,可以查看链接(https://clickhouse.com/docs/en/getting-started/example-datasets/brown-benchmark)。
mgbench三个表分别情况说明:
| 表名 | 数据行数 | csv数据大小 |
|---|---|---|
| mgbench.logs1 | 22023859 | 7.0G |
| mgbench.logs2 | 75748118 | 5.7G |
| mgbench.logs3 | 108957039 | 7.7G |
单data part大小为100w行。
我们对这十多个case, 分别在SSD阵列和CubeFS(HDD), CubeFS(SSD)上进行了500次查询取平均, 得出如下查询数据。
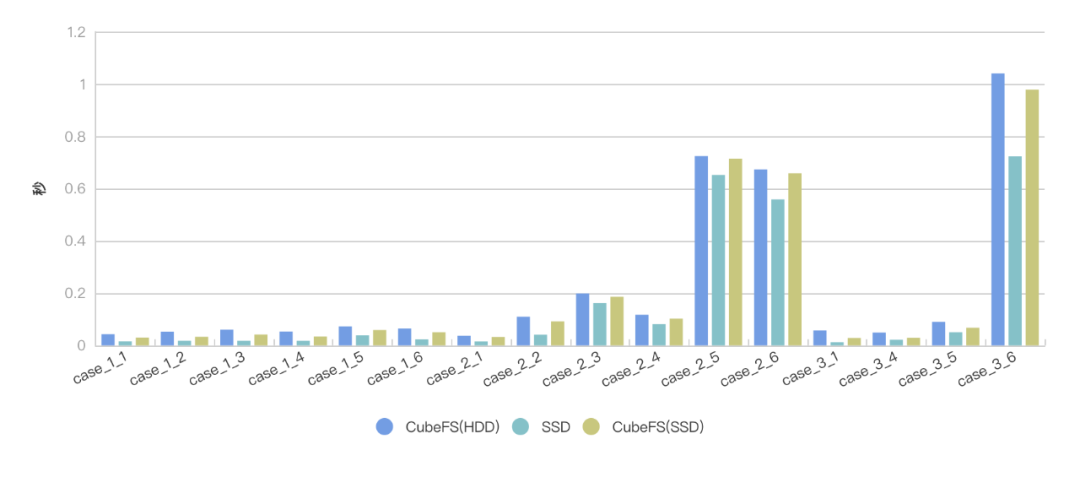
由此可见, 在延迟上CubeFS并不高,在小文件读取上, 查询延迟也基本和SSD相当,完全可以满足业务需求,而在大文件大规模数据读取上,因为带宽的优势, CubeFS更容易获得比较满意的用时。
06.未来规划
- 集群配置CubeFS需要挂载盘,比较繁琐。后续计划嵌入SDK代码到ClickHouse,绕过fuse,消除用户态到和内核态的多次切换。
- ClickHouse集群非常依赖ZK达成数据同步等特性,需要调研和使用性能更好的ClickHouse-Keeper。
- 存算分离模式下, 支持ClickHouse计算资源弹性扩缩,做好计算资源租户隔离,实现降本增效。